Jicheng Yuan, Duc Manh Nguyen / June 29, 2023
What is VisionKG?
VisionKG is a framework that uses Semantic Web technology to interlink and integrate data across different sources. It provides a novel way to manage visual datasets for training, validating, and testing computer vision models. With the rapid growth of huge visual datasets, working with data from diverse sources is desirable to increase the robustness of computer vision models. Besides, computer vision has recently achieved significant improvements thanks to the evolution of deep learning. Along with advanced architectures and optimizations of deep neural networks, visual datasets contribute greatly to the performance of computer vision models. However, annotations are available in heterogeneous formats and are not consistent across datasets. VisionKG addresses this challenge by providing a unified framework to organize and manage visual datasets. It demonstrates its advantages via various scenarios with the system framework accessible both online and via APIs. Figure 1 presents an overview of our VisionKG framework and the process of creating and enriching our unified knowledge graph for visual datasets.
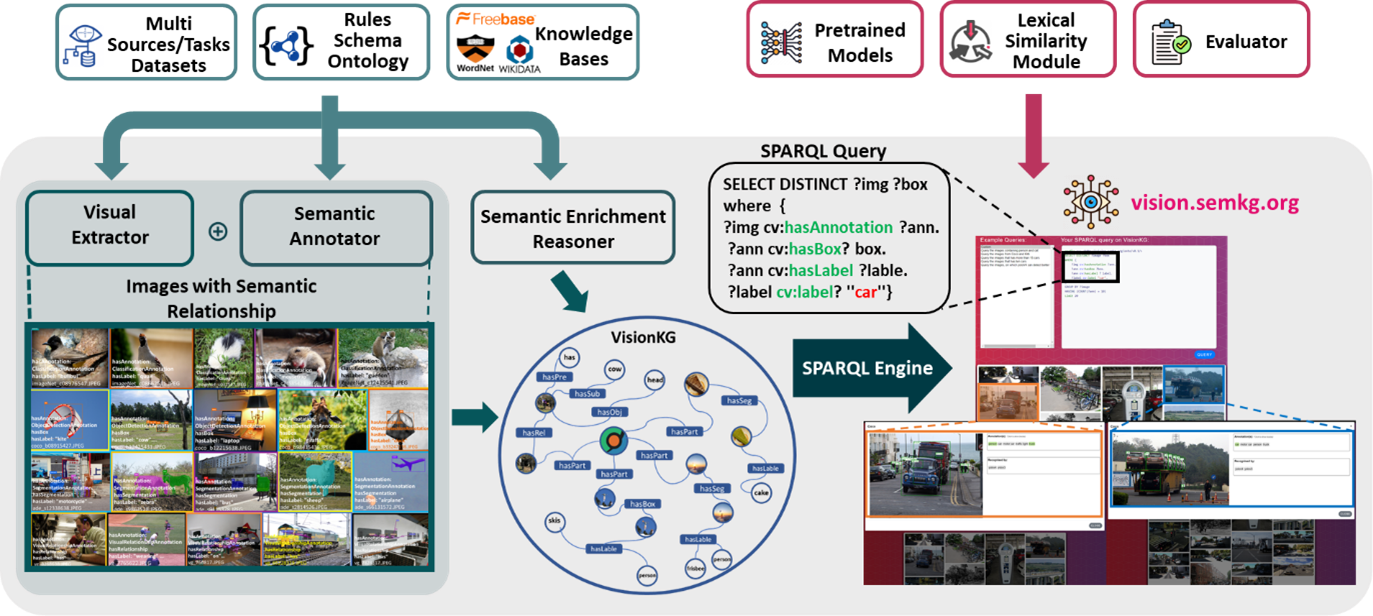
Fig. 1. Overview of VisionKG
We start by collecting popular computer vision datasets for CV from the PaperWithCode platform. Next, we extract their annotations and features across datasets using a Visual Extractor. We use RDF Mapping Language (RML) to map the extracted data into RDF. RDF data is generated using a Semantic Annotator implemented using RDFizer. To enhance interoperability and enrich semantics in VisionKG, we link the data with multiple knowledge bases, such as WordNet and Wikidata. The Semantic Enrichment Reasoner expands the taxonomy by materializing the labels in each dataset using the ontology hierarchy. For instance, categories like pedestrian or man isSubClassOf person (Figure 2.2). Based on the interlinked datasets and Semantic Enrichment Reasoner, users can access the data in VisionKG in a unified way (Figure 2.3). The SPARQL Engine maintains an endpoint for users to access VisionKG using the SPARQL query language.

Fig. 2. FAIR for Visual Data Assets.
How VisionKG works?
Figure 3 demonstrates our visual datasets explorer equipped with a live interactive SPARQL web interface. Users can initiate their exploration by selecting a desired task, such as Detection, Classification, Segmentation, or Visual Relationship, from a drop-down menu in Figure 3.1. Upon task selection, the system will promptly generate a list of all compatible datasets that support the chosen task, as Figure 3.2 illustrated. Next, users may choose a dataset, such as COCO or KITTI from the list. This will prompt the system to display all available categories within that dataset in Figure 3.3. To filter or select the desired categories, users can simply enter a keyword into the text box depicted in Figure 3.4. This process is further facilitated by allowing users to drag and drop a category from Figure 3.3 to the query box in Figure 3.6. The system will then auto-generate a SPARQL query, accompanied by an explainable text in Figure 3.5, designed to select images containing the specified category. It is noteworthy that multiple categories from different datasets can be selected. Users may modify the query by removing categories or adjusting the query conditions by selecting available options from boxes in Figure 3.5 or Figure 3.6. Additionally, users can also adjust the number of images to be retrieved.
Once the query is finalized, the user may click the “Query” button, and the results will be displayed in table format in Figure 3.7. Additionally, users may select the “Visualization” tab to view the results graphically, as shown in Figure 3.8. By clicking on an image, users may access additional information, such as annotations of that image and annotations generated from popular deep learning models shown in Figure 3.9. Overall, the platform offers an intuitive and efficient method for dataset selection and querying for machine learning tasks.
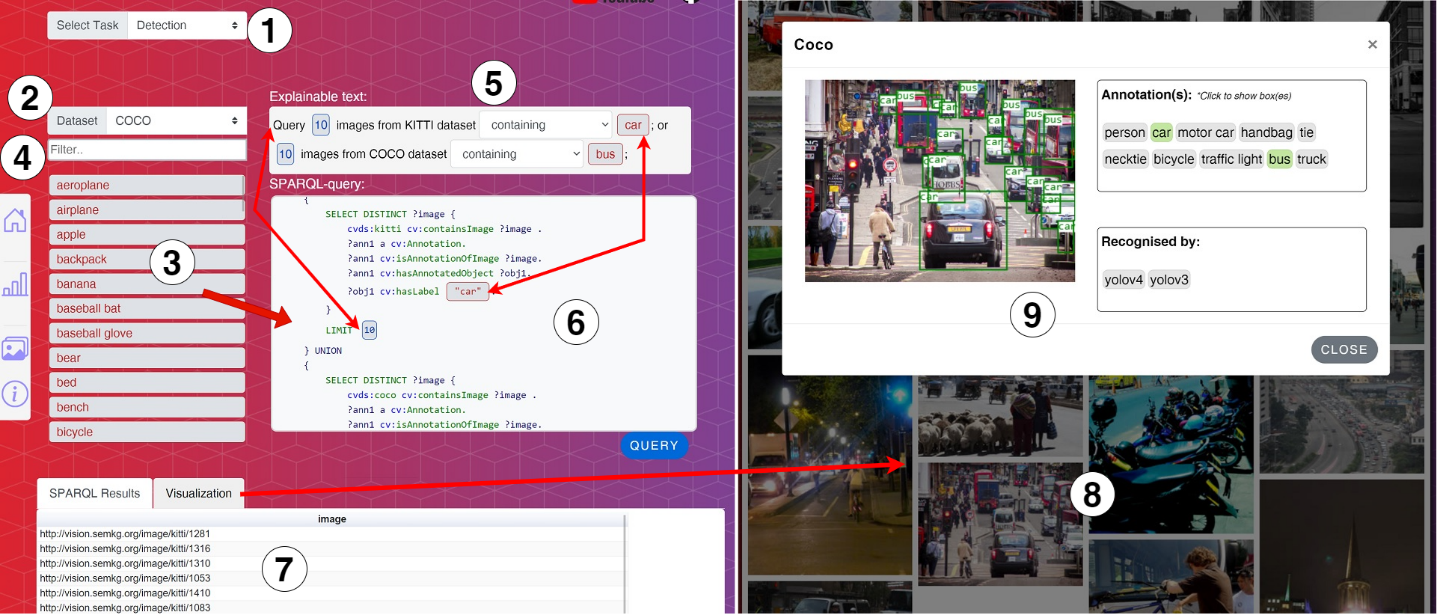
Fig. 3. VisionKG Web Interface.
Besides, powered by SPARQL, VisionKG supports automated end-to-end pipelines for visual tasks. Users can start a training pipeline by writing queries to construct various composite visual datasets. As demon- strated in Figure 4.1, users can query images and annotations with a few lines of SPARQL query to use RDF-based description to get desired data, such as images containing box-level annotations of car and person from interlinked datasets in VisionKG. In combination with current popular frameworks (e.g., Py-Torch, TensorFlow) or toolboxes (e.g., MMDetection, Detectron2), users can further utilize the retrieved data to construct their learning pipelines in just a few lines of Python code without extra effort, as Figure 4.2 demonstrated. Users need to define solely the model they want to use and the hyperparameters, they want to set.
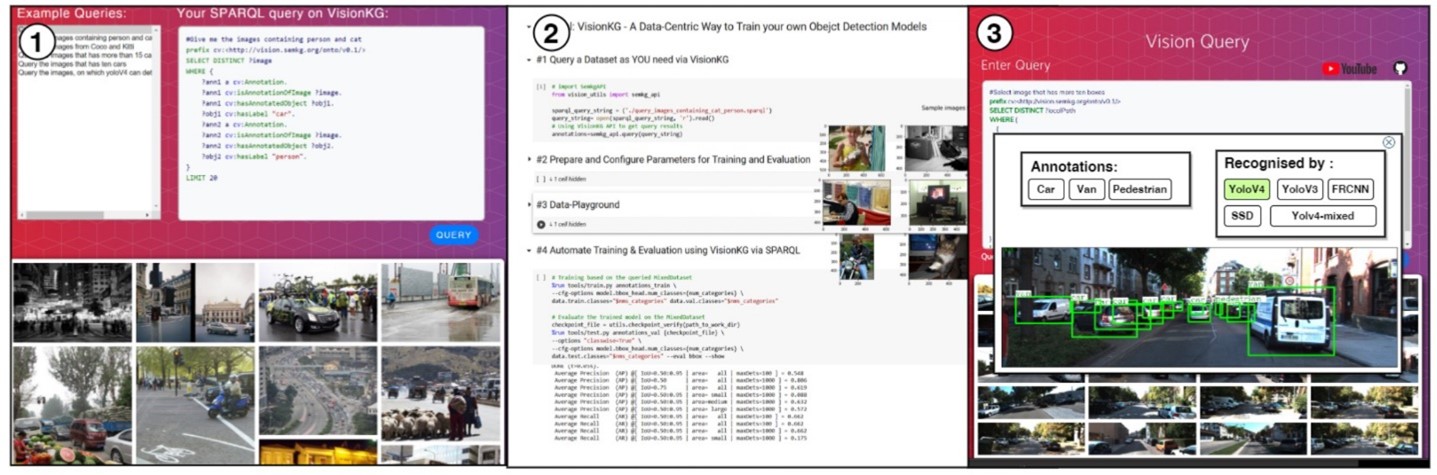
Fig. 4. Construct CV Pipelines Employing VisionKG.
Additionally, users can use VisionKG for their testing pipeline. The inference results can be integrated with data from VisonKG to provide quick insight about the potential model for specific scenarios. Figure 4.3 demonstrates that one can gain quick overview of a trained YOLO models to detect car on images containing car in crowded traffic scenes.
Benefits of using VisionKG
- Improved data management: VisionKG provides a unified framework utilizing knowledge graph and semantic web technology to organize and manage visual datasets across diverse sources.
- Reduced overhead: By using knowledge graphs and Semantic Web technologies to interlink, organize, and manage visual datasets, VisionKG reduces the overhead associated with traditional methods for training visual models. This can result in faster data collection and preparation and more efficient use of resources.
-
Enhanced model performance: The auxiliary knowledge from knowledge bases, such as Wikidata and WordNet, with respective concepts and rich semantics, can result in improved model performance, particularly when applied to target domains that differ from the source domain.
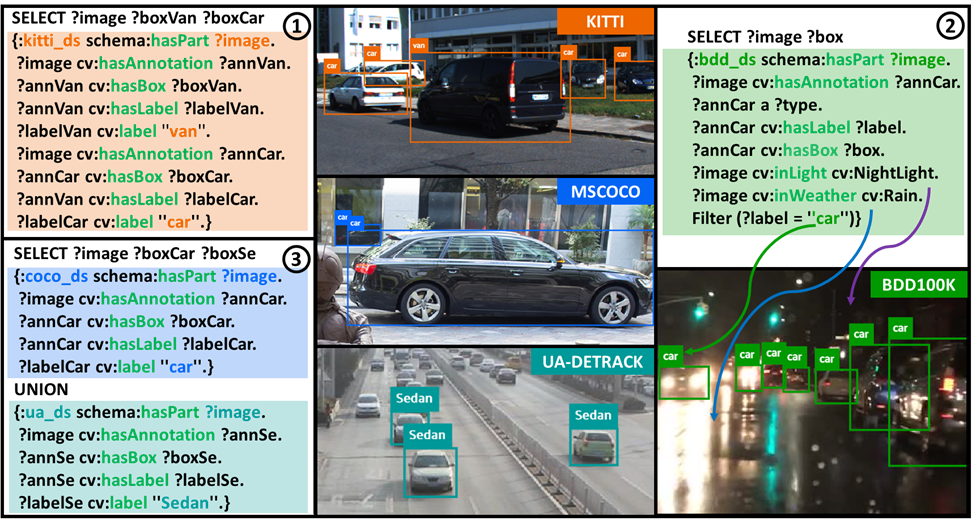
Fig. 5. Dataset-Exploration using VisionKG.
More Features about VisionKG